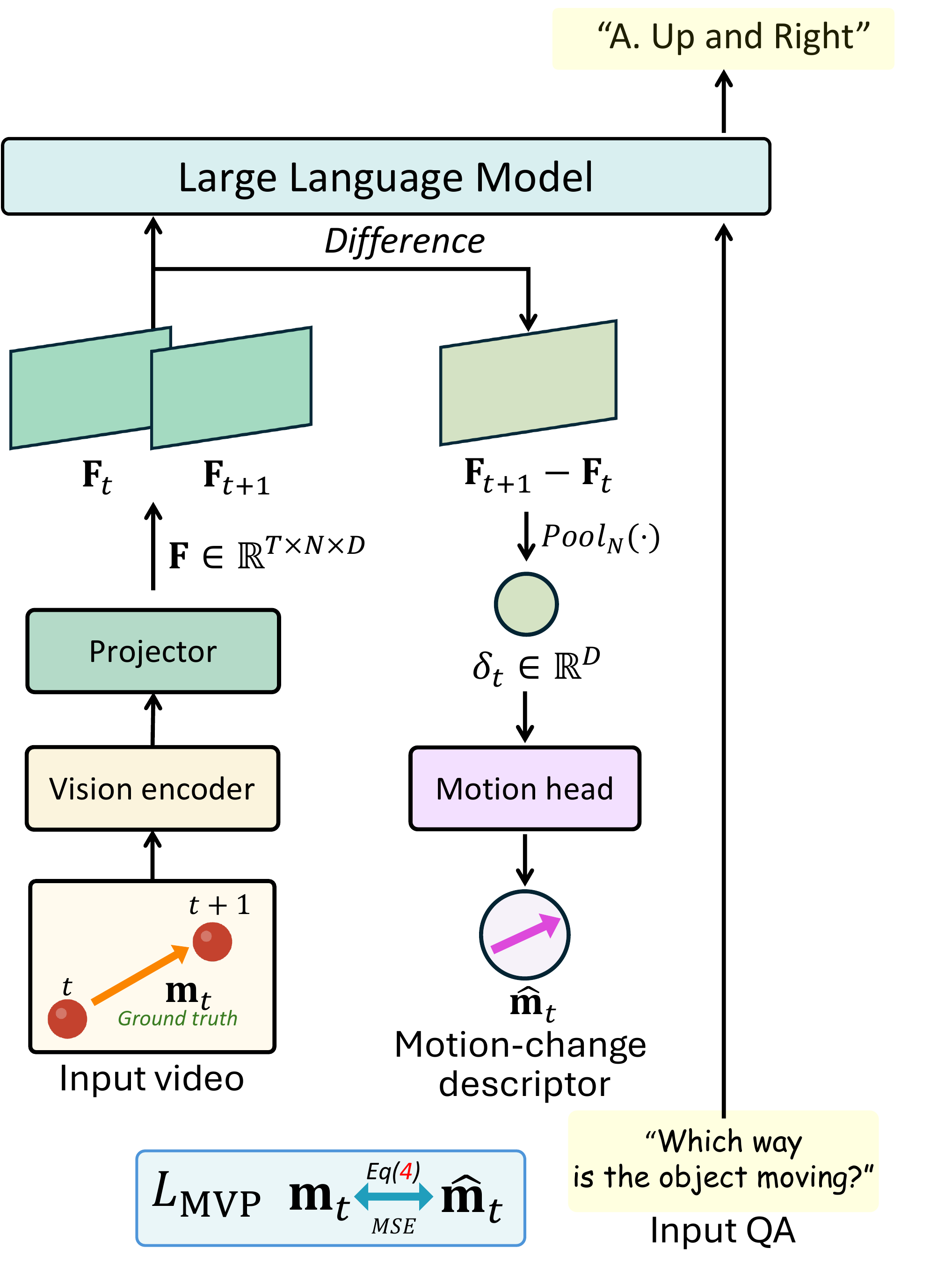
Two easy explanations — both fail.
Before opening the model, we test the obvious external hypotheses: maybe direction-supervised data is too rare, or maybe the prompt simply isn't asking the right way. Neither moves the needle.
Hypothesis 1: data is missing.
Only 0.91% of LLaVA-Video-178K is direction-related — after
keyword + semantic filtering, and human verification confirms this
as an upper bound. Supervision is scarce, but
scarcity alone tells us nothing about where in the model
the failure sits.
Hypothesis 2: the prompt is wrong.
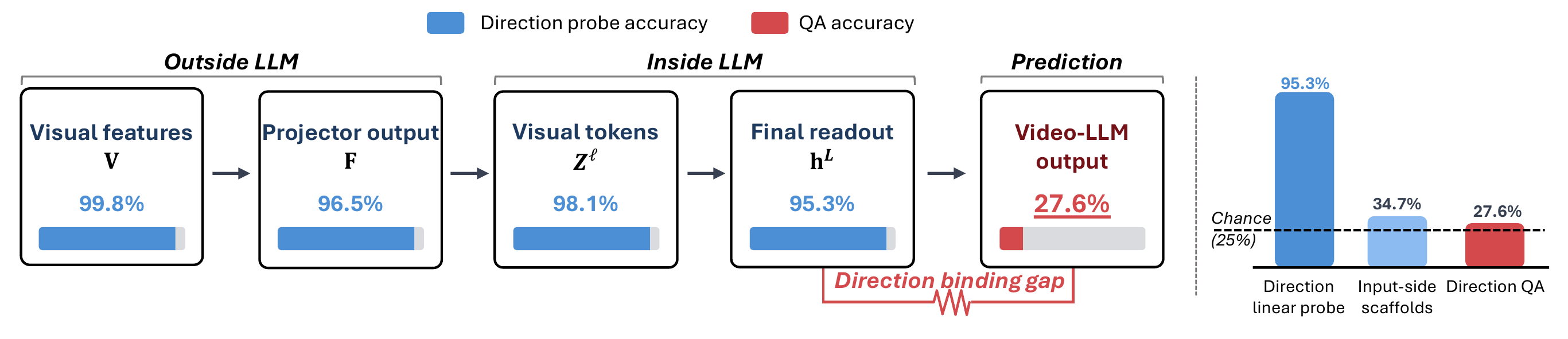
Best lift on P-Syn from any combination of input-side
scaffolds — visual boundary cues, step-by-step location
reasoning, and coordinate-grid prompts. Vanilla
27.6% → scaffolded 34.7%, still hovering at the
25% chance line. Prompting cannot close the gap.
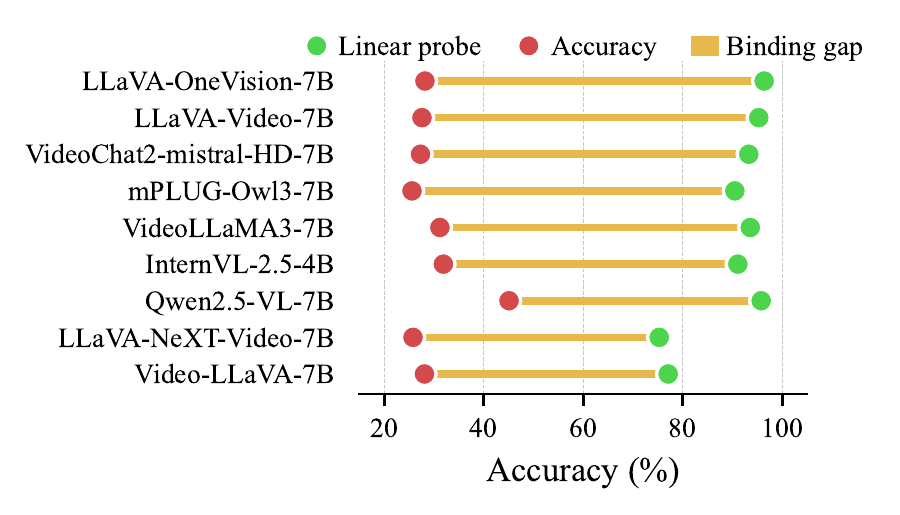
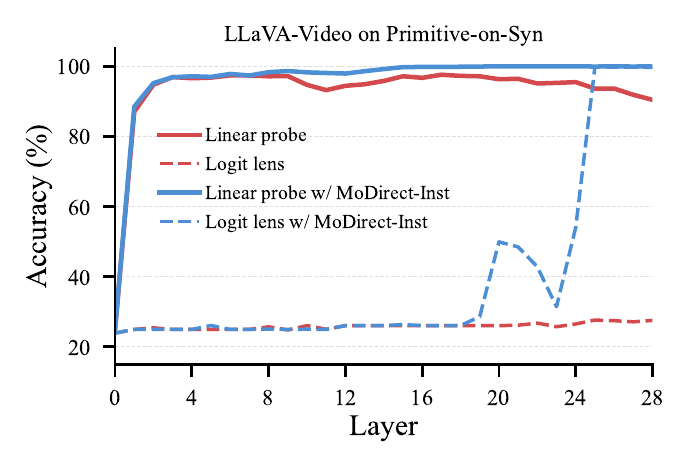
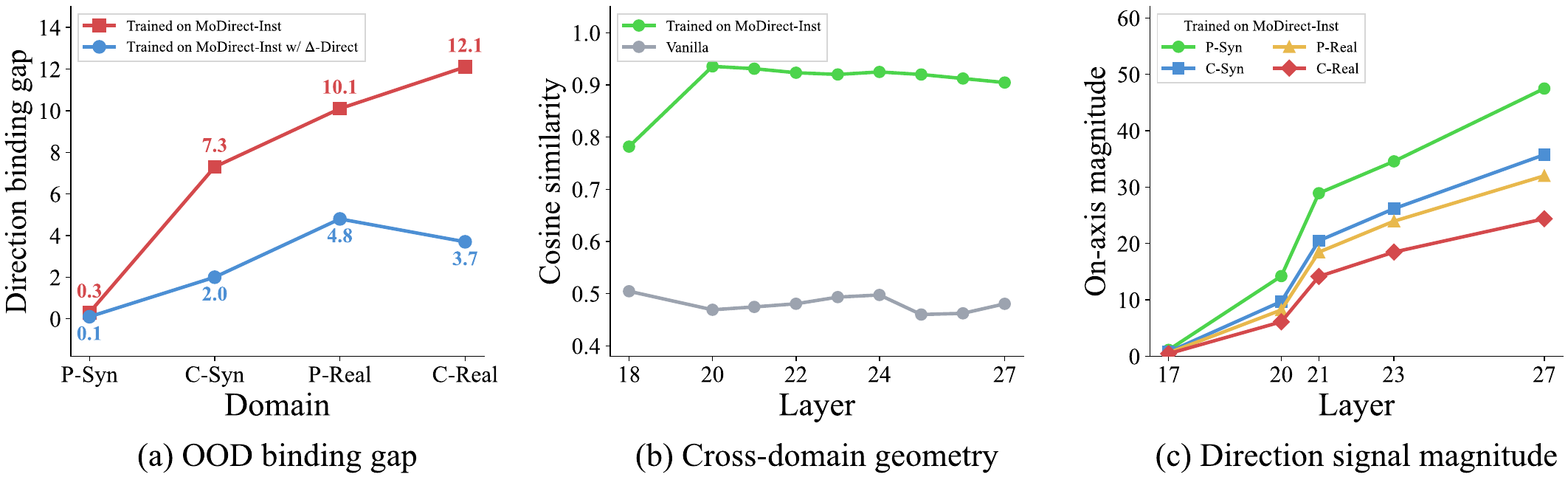
Neither lever moves the needle. The cause must be representational — so we open the model.